Storing data in Hadoop generally means a choice between HDFS and Apache HBase. The former is great for high-speed writes and scans; the latter is ideal for random-access queries — but you can’t get both behaviors at once.
Hadoop vendor Cloudera is preparing its own Apache-licensed Hadoop storage engine: Kudu is said to combine the best of both HDFS and HBase in a single package and could make Hadoop into a general-purpose data store with uses far beyond analytics.
Kudu was created as a direct reflection of the applications customers are trying to build in Hadoop.
Kudu’s simple data model makes it breeze to port legacy applications or build new ones: no need to worry about how to encode your data into binary blobs or make sense of a huge database full of hard-to-interpret JSON. Tables are self-describing, so you can use standard tools like SQL engines or Spark to analyze your data.
Even in its first beta release, Kudu includes advanced in-process tracing capabilities, extensive metrics support, and even watchdog threads which check for latency outliers and dump “smoking gun” stack traces to get to the root of the problem quickly.
Kudu unique ability to support columnar scans and fast inserts and updates to continue to expand your Hadoop ecosystem footprint. Using Kudu, alongside interactive SQL tools like Impala, allows you to build a next-generation data analytics platform for real-time analytics and online reporting.
Kudu is best for use cases requiring a simultaneous combination of sequential & random reads & writes.
Some sample areas where Kudu is a good fit :
- Customer service & feedback
- Fraud detection & presentation
- Clickstream analysis
- Recommendation engines
- Reporting using ODS
- Network monitoring
- Government- traffic updates & analysis
- Gaming over network
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu (incubating) completes Hadoop’s storage layer to enable fast analytics on fast data.
Talend Kudu Components by One point
Introduction
Abstract
In this tutorial you can learn how to use the Talend Kudu components created by Onepoint Ltd. These components are:
| Name | Description | |
| tKuduInput | This is the component used to read data from Apache Kudu. | |
| tKuduOutput | This is the component used to save data from Apache Kudu. |
These components are free and can be downloaded from Talend Exchange.
About Apache Kudu
Apache Kudu is a revolutionary distributed columnar store for Hadoop that enables the powerful combination of fast analytics on fast data. Kudu complements the existing Hadoop storage options, HDFS and Apache HBase. Additional information on Apache Kudu, its architecture and use cases can be found at https://getkudu.io/.
At the time of this creation of this document (June 2016) the Apache Kudu is still in beta stage. Onepoint Ltd is planning to release a new version of the components as soon as Apache Kudu 1.0 is released.
Pre-Requisites
Kudu Installation
You will need to have Apache Kudu installed in order to be able to use the components. Apache Kudu runs on multiple Linux distributions and can be installed following the instructions on this page:
https://getkudu.io/docs/installation.html
A developer friendly option to be able to develop on one single machine would be to use a Cloudera VM with Linux on which you run Kudu and then have Talend running on the hosting OS.
Talend Installation
You will also need to have at least Talend Open Source 6.0 installed on your machine, in order to be able to use the components. Any of the Talend Enterprise versions would of course also work for this tutorial.
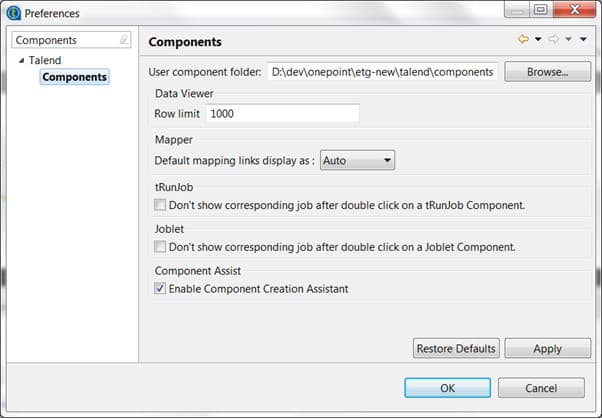
Talend Components Folder Setup
Finally you will need to have the components folder properly setup, so that you can install the components from Talend Exchange. Here are the instructions to do so:
Kudu Components Installed
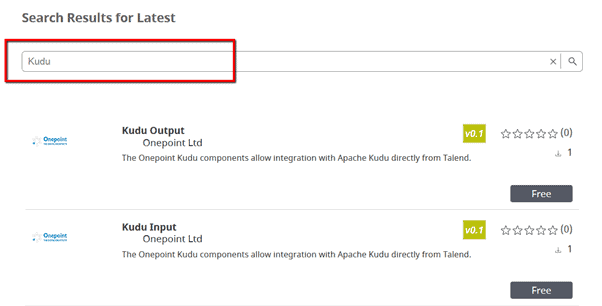
Finally you should have the Kudu components installed in your Talend Components folder. The easiest way to find the components in Talend Exchange is simply by searching for “Kudu”:
Support Materials
Example Schema
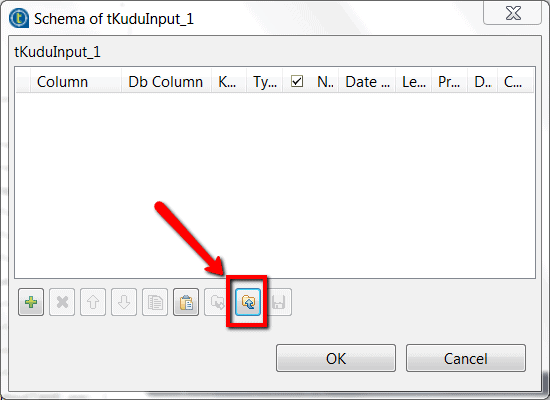
The schema used in the examples is always the same. It represents the data of a customer and might be tedious to create manually. For this reason we provide an xml export of the schema which you can use in this tutorial.
In order to import the schema into any of the components mentioned in the examples, please use this button:
tKuduOutput
This component allows you to write data to Apache Kudu. It accepts one input flow connection. Furthermore it also supports optional output and reject flow connections.
Optionally the component allows you to create and delete Kudu tables too.
Example Job 1
In this job we will write some dummy data to a Kudu table which will be created in case the Kudu table does not exist yet.
Step by step instructions
1. We will start by creating a standard Talend job (if you are using the “Enterprise version”). If you are using the open source version of Talend you just typically create a normal job.
a. Enterprise version
b. TOS version
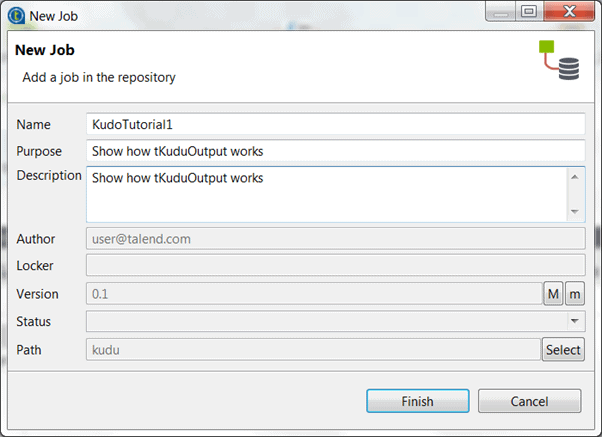
2. We will fill the details of the New Job dialogue.
3. We select the tFixedFlowInput component from the Palette and drop it on the job view panel.
4. We click on the created tFixedFlowInput component and click on the “Edit schema” button.

5. The schema we are going to create describes a customer. It contains the following fields:
a. Email (the primary key)
b. Surname
c. Given name
d. Age
e. Country
f. Married
g. Weight
h. Photo
i. Profession
j. Insertion Date
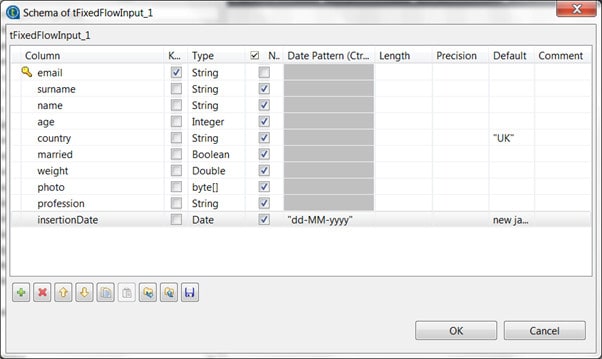
Please note that Kudu always needs a primary key which is in this case the email field.
Hint: alternatively you can import the schema file provided in this tutorial (see chapter Support Materials).
Now we create the data for this same component. For this purpose we are going to use an inline table.
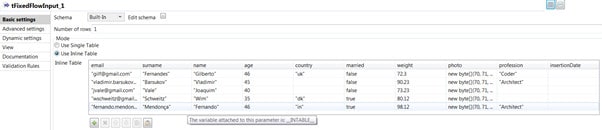
7. At this point in time we have a fully configured tFixedFlowInput component which can be linked to a tKuduOutput component. Now we search in the palette for the tKuduOutput component which you can typically find in the category “Databases/Kudu”.
8. We select the tKuduOutput component from the Palette and drop it on the job view panel.

9. Now we connect the tFixedFlowInput component with the tKuduOutput component.

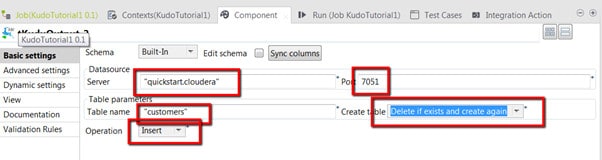
10. The tKuduOutput connection needs to be configured. We click on the tKuduOutput component and change the data in the “Basic settings” view. You have to set all parameters on this panel:
Server – The name of the server on which Apache Kudu is running. Please note that on test environments you might have to change the hosts file to map the name to a specific IP address.
Port – The port on which Apache Kudu is running.
Table name – The name of the table which is going to store the data.
Create table – The table creation options. We have chosen “Delete if exists and create again”, because we want to guarantee that this example runs without errors.
Operation – The data operation to be executed by this component. In this case we are going to insert data.
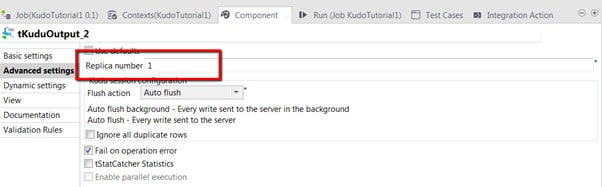
11. (Optional) If you have started Kudu on a Cloudera distribution VM or on a simple VM, most probably you will need to set the number of replicas to 1.
12. Now we can run the job and see, if everything is ok.
13. In case of success you should see something like this on Talend Studio:
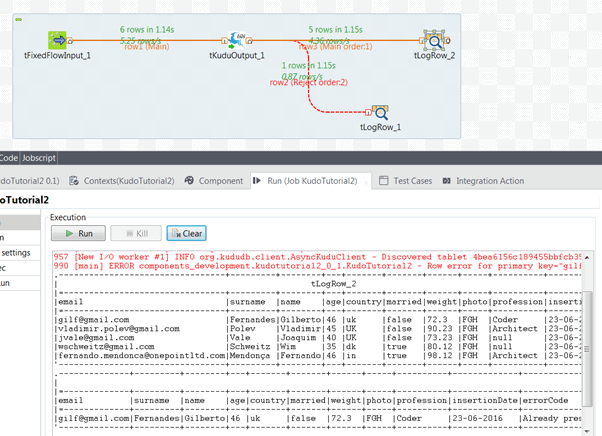
In case of errors, please check the Common Errors chapter.

